When in doubt, use brute force.
One of my most productive days was throwing away 1000 lines of code.– Both quotes by Ken Thompson (UTF-8, Plan9, grep(1), Golang, etc.)
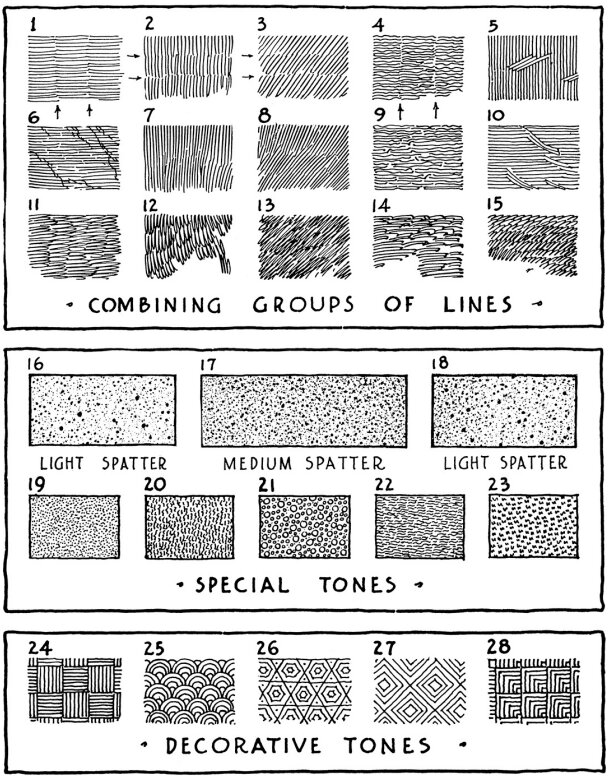
Page 61 of “Rendering in Pen & Ink”: examples of lines/groups of lines, combined to create texture variety
by
Arthur L. Guptill

Page 75 of “Rendering in Pen & Ink”: examples of how to vary value, while maintaining texture variety
by
Arthur L. Guptill
Historical accounts
There’s always been a more or less popular cultural background in IT, generally tied to the “UNIX Way”, including:
- The Tao of Programming, inspired by Laozi (6th to 4th BC)’s Tao Te Ching, a pillar of Taoism;
- The Unix Koans of Master’s Foo, inspired by Buddhist’s Kōans;
- Various texts on “hacker” culture:
All the aforementioned texts are extremely insightful: they condense knowledge accumulated by the first generations of computer scientists, at a time were computers were not as prevalent nor user-friendly as they are today, and at a time where resources were scarce. Hence, people were at that time really passionate, had an academic background not in computer science, had a deep understanding of all the software/hardware they were using, had to rely on themselves instead of googling their way around, etc.
The real hero of programming is the one who writes negative code.
– Doug McIlroy, (Unix pipelines, diff(1), sort(1), tr(1), Plan9, etc.)
In reference the this famous anecdote:
When the Lisa team was pushing to finalize their software in 1982, project managers started requiring programmers to submit weekly forms reporting on the number of lines of code they had written. Bill Atkinson thought that was silly.
For the week in which he had rewritten QuickDraw’s region calculation routines to be six times faster and 2000 lines shorter, he put “-2000″ on the form. After a few more weeks the managers stopped asking him to fill out the form, and he gladly complied.
(source)
Personal experience
First story
This takes place when I was studying computer science at university, about ten years ago. We had to implement Huffman’s algorithm in C. I had been programming in C for a few years back then: my solution was something around a few hundred lines of code, arranged in a few re-usable modules (that were never re-used), such for handling trees, etc.
It also did a very poor job at being a correct implementation.
On the other hand, the teacher’s solution, well, was orders of magnitude simpler. As this is nearly a decade away, I may be confused, but this should be his implementation:
int main(int argc, char *argv[])
{
int weight[2*CHAR_MAX] = {INT_MAX,0}; // initialize to zero except first one
int padre[2*CHAR_MAX] = {0}; // every node is a root
int last = CHAR_MAX; // index of last node (always a root)
int min1, min2; // indexes of the two lightest roots
int i, j; // indexes for loops
// initialize weights ------------------------------------------------------
while ( *argv[1] ) weight[ *argv[1]++ ]++;
// compute Huffmann tree ---------------------------------------------------
// Remark: weight[min1] <= weight[min2]
while (1)
{
for (i=min1=min2=0; i<=last; i++) if ( !padre[i] ) // For all roots
if ( weight[i] && weight[i]<weight[min2] )
weight[i]<weight[min1] ? (min2=min1,min1=i) : (min2=i);
if (min2==0) break; // If there is a single root => END
weight[++last] = weight[min1] + weight[min2];
padre[min2] = -(padre[min1] = last);
}
// Print codes of occurring letters ----------------------------------------
for (i=1; i<=CHAR_MAX; i++) if ( weight[i] ) // For all occurring letters
{
int code=0, len=0;
printf("\n %c => ", i);
for (j=i; padre[j]; j=abs(padre[j])) code|=(padre[j]>0?0:1)<<len++;
while (len--) putchar(code&1<<len? '1' : '0');
}
}The contrast in simplicity was striking; it took me a few years to fully understand the issue: by building layers of abstractions instead of focusing on solving the issue [using the abstractions naturally provided by C, and making a few bold assumptions], I was increasing my workload, for no benefit. Not only did I had to implement Huffman’s code, but I also had to correctly implement a few different abstractions.
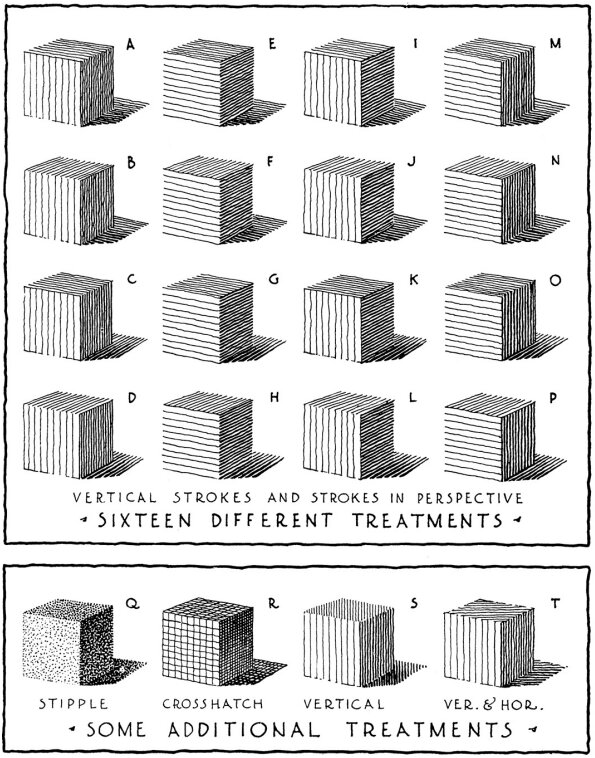
Page 133 of “Rendering in Pen & Ink”: using value/texture to communicate a simple cubic volume
by
Arthur L. Guptill
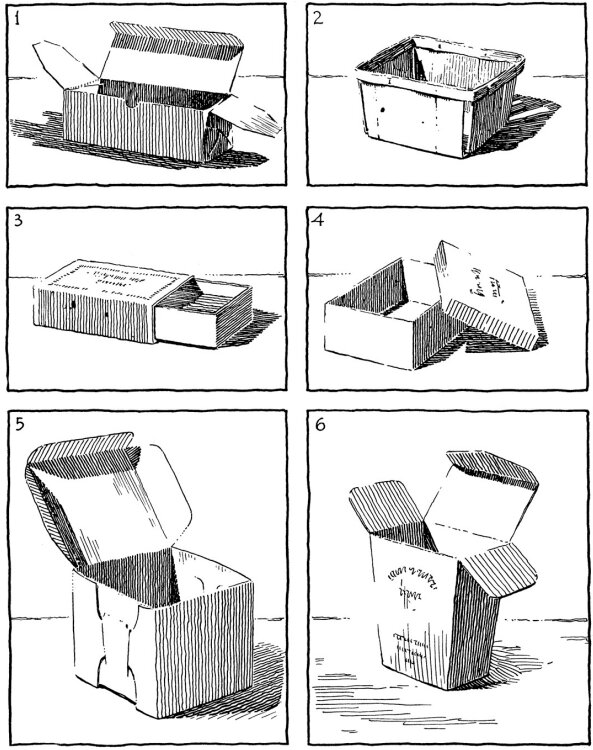
Page 141 of “Rendering in Pen & Ink”: using value/texture to communicate realistic, box-like volumes
by
Arthur L. Guptill
Second story
During my studies again, I once had an internship at the CEA (French Alternative Energies and Atomic Energy Commission), working on dislocation dynamics simulation.
Informally, dislocations are “flaws” in an otherwise regular arrangement of atoms, such as lines of missing atoms. As a practical examples, blacksmiths not only shape a piece of metal by hitting it, but they also strengthen it: that strengthening is precisely due to the creation and movements of dislocations within the object.
Now for the real story: I had to write a (LaTeX) report, and I decided to challenge myself by strictly using ed(1) to write it. This was an interesting experience:
- You have to learn how to use ed(1)’s features to your
advantage. For instance, you have to use regular expressions to
navigate efficiently in the document. As an example, a common pattern
in some C codebases is to declare functions with:
While this may seem benign, it actually allows you to move to a function’s definition in a breeze with
void cat(int f, char *s) { /* ... */ } /* * Over, for instance: * void cat(int f, char *s) { ... } */^cat\(', or to easily generate a list of existing functions, depending on the codebases, with something aroundgrep '^[a-zA-Z0-9_]\(' *.c. Some people might find this unpolished, but the ratio effectiveness/cost is unmatchable. - It forces to be more thoughtful when writing: the software makes it painful to fix a typo or an omission: you’re then naturally more mindful. Next time you have a 10LoC shell code to write, give ed(1) a shot and see for yourself;
- Similarly, because there’s no visual display, it forces your brain to actually spatially arrange the code, and more generally, to have a mental image of the codebase. As a side effect, because we’re limited, it encourages us to make the codebase small and simple enough to fit in a single person’s brain.
In some communities, that kind of line of thinking is still alive and well:
In some ways I think the relative difficulty of using dynamic allocation in C compared to other languages is a good thing — it forces you to think whether it’s really necessary before doing so, and in many cases, it turns out not to be. That way encourages simpler, more efficient code. In contrast, other languages which make it very easy to dynamically allocate (or even do it by default) tend to cause the default efficiency of code written in them to be lower, because it’s full of unnecessary dynamic allocations.
But it seems overall to be far less intense that what it used to be:
Some people who grew up in the `Real Programmer’ culture remained active into the 1990s. Seymour Cray, designer of the Cray line of supercomputers, was among the greatest. He is said once to have toggled an entire operating system of his own design into a computer of his own design through its front-panel switches. In octal. Without an error. And it worked. Real Programmer macho supremo.

Page 145 of “Rendering in Pen & Ink”: using value/texture to create round volumes
by
Arthur L. Guptill
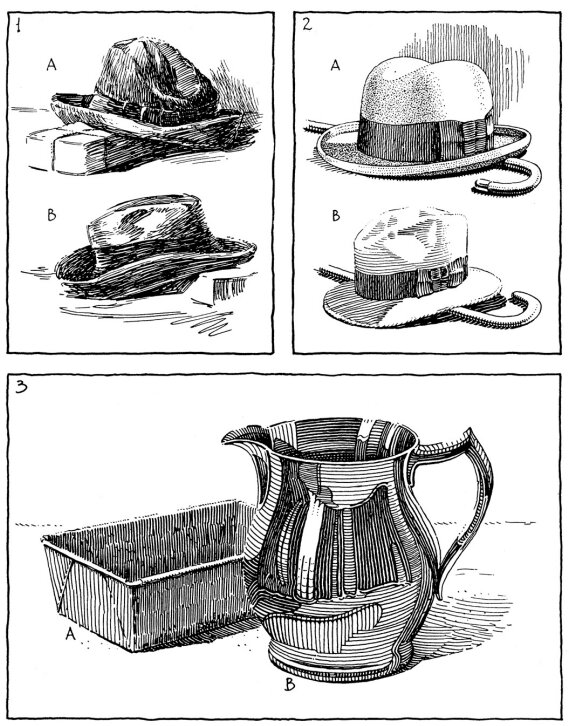
Page 151 of “Rendering in Pen & Ink”: same objects, different rendering; reflective surface
by
Arthur L. Guptill
Abstracted away
Let’s consider an almost trivial example: removing all the spaces in a string. “Modern” languages allows to do that in a breeze:
#!/usr/bin/env perl
sub stripwhites0 {
my ($s) = @_;
$s =~ s/\s//g;
return $s;
}
sub stripwhites1 {
my ($s) = @_;
return join("", split(/\s+/, $s));
}
# foobarbaz
print stripwhites0("foo bar \t\tbaz")."\n";
print stripwhites1("foo bar \t\tbaz")."\n";#!/usr/bin/env python
import re
def stripwhites(s):
return "".join(re.split(r"\s+", "foo bar \t\tbaz"))
# foobarbaz
print(stripwhites("foo bar \t\tbaz"))A typical C version would have that distinctive strcpy(3)-implementation flavor:
#include <stdio.h>
char *
stripwhites(char *s)
{
char *p, *q;
for (p = q = s; *q != '\0'; q++) {
if (*q == ' ' || *q == '\t')
continue;
*p++ = *q;
}
*p = '\0';
return s;
}
int
main(void)
{
char s[] = "foo bar \t\tbaz";
/* foobarbaz */
printf("%s\n", stripwhites(s));
return 0;
}/* $OpenBSD: strcpy.c,v 1.10 2017/11/28 06:55:49 tb Exp $ */
...
char *
strcpy(char *to, const char *from)
{
char *save = to;
for (; (*to = *from) != '\0'; ++from, ++to);
return(save);
}Exercise: Try answering the following questions,
for each version of stripwhites() (Perl, Python, C):
- How many allocations are performed?
- How much memory is being used?
- What’s the algorithmic complexity?
- What are the assumptions made by the C code? In which cases are they reasonable/unreasonable?
While such a simple exercise won’t necessarily generalize (I’m not suggesting that we all start to go back to write daily C: it makes sense in some cases, but for most practical cases, it doesn’t); the point is, a language with limited and unified abstraction capabilities, as a text editor or a wooden plane, polarizes the thinking process towards a simpler approach; furthermore in the case of C, close to the hardware’s behavior, which is arguably important general culture for a modern programmer.
I’m always delighted by the light touch and stillness of early programming languages. Not much text; a lot gets done. Old programs read like quiet conversations between a well-spoken research worker and a well-studied mechanical colleague, not as a debate with a compiler. Who’d have guessed sophistication b[r]ought such noise?
– Dick Gabriel (source; known for e.g. Common Lisp)
C’s legendary sharpness also encourages a strong level of discipline, a quality that unfortunately, out of misunderstanding, is too often substituted by more code/programmers. As such, I think C might be better than Python to teach (professional) programming.
Exercise: Write a C function ... split(...) which
splits a string made of space separated fields. Can you do so without
dynamically allocating memory (you can assume the input to
split to already have been allocated, e.g. by fixing it in the
code)? In which cases would this be reasonable/unreasonable?

“A Continent Is Bridged”, drawn for the Atlantic Telephone & Telegraph Company for the observance of the twenty-fifth anniversary of transcontinental telephone service
by
Franklin Booth
{kind=link}
Defining simple software?
Perhaps the most common pattern for simple software is either to be a primitive, single-task oriented tool (e.g. cat(1), or a collection of primitive tools to be combined in order to solve issues (e.g. Unix shell programming).
By comparison, complex software are an endless stream of features: simple software implements most of that stream at once in a fraction of the effort, through a set of a few primitive features.
This hints at a key difficulty of using simple software: it’s not always trivial to understand how to use a set of primitives to fix an apparently unrelated problem. This is especially true in computing environment that have had a limited public exposure: the software has been created and used by people may not have thought worthy of publishing solutions to (relatively) ordinary issues, for programs whose code is available and documentation (man pages) exhaustive; the Plan9 from Bell Labs ecosystem is a great example of that; OpenBSD too, to a lesser degree.
Comments
By email, at mathieu.bivert chez: